
 V pátém dílu seriálu o databázovém programu Base částečně odbočíme od hlavního proudu seriálu, kterým je práce s
Base. Budeme se totiž věnovat analýze požadavků a návrhu databáze: částečně obecným zásadám, ale hlavně pro naší
databázi Knihovna. Půjde tedy o teoretickou, ale důležitou část – tyto činnosti jsou pro budoucí funkčnost databáze
základní podmínkou. Kdo se nechce zabývat procesem analýzy a návrhu, může tento díl přeskočit (závěry připomenu i v
další části).
V pátém dílu seriálu o databázovém programu Base částečně odbočíme od hlavního proudu seriálu, kterým je práce s
Base. Budeme se totiž věnovat analýze požadavků a návrhu databáze: částečně obecným zásadám, ale hlavně pro naší
databázi Knihovna. Půjde tedy o teoretickou, ale důležitou část – tyto činnosti jsou pro budoucí funkčnost databáze
základní podmínkou. Kdo se nechce zabývat procesem analýzy a návrhu, může tento díl přeskočit (závěry připomenu i v
další části).
Odpovědi na otázky ze shrnutí čtvrtého dílu
Práce s Base 3, Teorie 3, 4
-
Uveďte základní vlastnosti cizího klíče a porovnejte je s vlastnostmi klíče primárního. Kterou z vlastností cizího klíče nazýváme pravidlo referenční integrity?
Pro cizí klíč (foreign key) platí:
- jeho hodnoty se mohou v jeho sloupci opakovat,
- některé buňky ve sloupci cizího klíče mohou být prázdné (nemusí obsahovat žádnou zadanou hodnotu neboli mají hodnotu NULL),
- cizí klíč nesmí obsahovat hodnotu, která by nebyla obsažena ve sloupci odpovídajícího primárního klíče připojené tabulky (pravidlo referenční integrity).
Vlastnosti primárního klíče jsou téměř opačné:
- jeho hodnoty musí být unikátní – nesmí se v tabulce opakovat,
- hodnota primárního klíče nesmí v žádné buňce ve sloupci tohoto klíče chybět,
- primární klíč může jistě obsahovat hodnotu, která není ve sloupci odpovídajícího cizího klíče v jiné tabulce.
-
Vysvětlete, pro jakou tabulku se používá název číselník, uveďte příklady.
Jde o tabulku, jejíž hodnoty jsou z konečné množiny prvků. U takové tabulky můžeme pro jednoduchost sloupec těchto samotných hodnot zvolit jako primární klíč (tabulka může mít jen jediný sloupec). Příkladem číselníku může být barva výrobku, žánr knihy apod.
-
Jaké jsou druhy vazeb (násobnosti vazeb) mezi tabulkami? Uveďte příklady jejich použití.
Jde o vazbu 1 – 1, 1 – M a M – M. První je méně častá, jeden záznam první tabulky je propojen vždy jen s jedním záznamem tabulky druhé. Použijeme ji např. pro rozdělení tabulky, obsahující také citlivé údaje, na tabulky dvě. V jedné budou běžné údaje, tato tabulka bude menší a práce s ní bude rychlejší. Ke druhé tabulce se bude přistupovat jen občas. Druhá vazba umožňuje, aby jeden záznam z jedné tabulky mohl být propojen s více záznamy z tabulky druhé, např. jedna firma může mít víc telefonních čísel, jedno oddělení může mít víc pracovníků apod. Třetí vazba vyjadřuje případy, kdy jeden záznam první tabulky může být propojen s více záznamy tabulky druhé, ale platí to i naopak. Např. jeden spisovatel může být autorem více knih, ale jedna kniha může mít zároveň více autorů.
-
Ukažte v Base vytvoření vazby mezi dvěma tabulkami (jak tažením myší, tak dalším oknem Relace).
Popis činností je ve čtvrtém dílu.
Úvodní poznámky k návrhu databáze
Důležitost návrhu. V textu o vytvoření tabulky v režimu návrhu ve třetím dílu a hlavně v poznámce u textu o založení databáze v druhém dílu seriálu se opakovala upozornění na to, že vlastnímu vytvoření databáze by měla předcházet pečlivá analýza požadavků na databázi a návrh, aby databáze dobře plnila své úkoly. Pozdější úpravy struktury databáze by byly pravděpodobně velmi pracné a nepříjemné! Zastavme se tedy v tomto díle nad plánováním databáze Knihovna i nad obecnými zásadami této činnosti.
Složitost návrhu. Má to ale jeden háček: návrh databáze je složitá věc, studenti informatiky na vysokých školách se této problematice věnují (spolu se souvisejícími tématy) jistě aspoň dva semestry (čili jeden rok studia). O obtížnosti navrhování databází (nebo programů u programátorů) svědčí také to, že jen menšina z absolventů se v profesním životě věnuje těmto činnostem a právě tito odborníci jsou nejlépe placeni. Zbývající většina pracovníků s databázemi nebo programátorů pracuje spíše jako „dělníci“ tak, že podle návrhů píší zdrojový kód, tvoří databáze nebo je jako správci spravují. (Kvůli větší obtížnosti tématu tohoto článku bych měl uvést materiály k podrobnějšímu studiu, z nichž mnohé byly také mými prameny. Uvádím je na konci článku.) Má tedy smysl se v tomto seriálu o základech práce s databázemi a s Base věnovat obtížnému návrhu?
Myslím, že bychom to měli zkusit. Důvody pro jsou např. tyto:
-
Návrh databáze do práce s databází prostě patří a bylo by dobré se s ním aspoň letmo pro představu seznámit.
-
Studenti středních škol, kteří by chtěli maturovat z informatiky, by měli podle současných požadavků na státní maturitu o návrhu databáze něco vědět (jak bylo uvedeno už v prvním dílu, v Katalogu požadavků zkoušek společné části maturitní zkoušky, platném pro školní rok 2011/2012, se u vyšší úrovně obtížnosti uvádí i Návrh databází takto: „Žák dovede navrhnout strukturu tabulek pro řešení databázového problému a jejich provázání přes primární klíče, dál vytvořit navrženou databázi ve zvoleném databázovém prostředí a naplnit ji daty.“). Předpokládám, že autoři katalogu požadavků si nepředstavovali, že se ve středoškolské informatice bude věnovat více času návrhu databází – to myslím není prakticky uskutečnitelné. Asi se myslí jen zcela jednoduché příklady. V následujícím textu se tedy pokusím jen naznačit, jak by příprava databáze mohla vypadat.
Obecně o návrhu databáze
Proces plánování budoucí relační databáze se postupně vyvíjel od sedmdesátých let dvacátého století. Obsahuje několik fází; ty jsou obdobné fázím při vývoji programu programátory.
Jednotlivé fáze tvorby databáze
-
Fáze shromažďování požadavků. Bez ní můžeme opomenout mnohé důležité stránky budoucí databáze. Požadavky získáme především pomocí rozhovorů se zadavatelem vytvoření databáze a s budoucími uživateli databáze: v našem případě např. s učitelem, který chce knihovnu používat.
-
Fáze analýzy požadavků, vznik konceptuálního modelu, který znázorníme ER diagramem. Analýzou požadavků se snažíme najít základní součásti (entity) budoucí databáze (částečně odpovídají budoucím tabulkám), vlastnosti entit (neboli atributy, budoucí sloupce tabulek) a také vazby mezi entitami (ze kterých vzniknou vazby mezi tabulkami).
-
Fáze tvorby logického modelu – v této fázi přejdeme od ER diagramu k vlastním tabulkám databáze a k vazbám mezi nimi. Návrh ještě nezávisí na použitém SŘBD.
-
Fáze tvorby fyzického modelu – zefektivnění a přizpůsobení použitému SŘBD. Touto fází se v tomto seriálu nebudu zabývat.
-
Fáze testování, tvorby dokumentace apod. – závěrečné činnosti, ani jim se zde nebudeme věnovat.
Do procesu návrhu patří ještě tzv. normální formy, které umožňují upřesnit a zaručit proces odstraňování redundance dat ve vznikající databázi a jak bylo uvedeno už v prvním díle, stále rozšířenější jsou databáze objektově orientované; budoucí studenti informatiky na vysokých školách se tedy mohou těšit v oblasti databází na mnoho zajímavých věcí.
Náš plán
V tomto dílu se krátce podíváme na první tři fáze tvorby databáze – sběr požadavků, analýzu požadavků a konceptuální model (ER diagram). Další díl uzavře návrh logickým modelem (tvorbou tabulek a vazeb podle konceptuálního modelu) – nebude to těžké, protože vytvořit tabulky i vazby jste se už naučili, nové bude převedení vazby M – M na dvojici vazeb 1 – M. V následujících dílech vytvoříte nadstavbu tabulek: dotazy, formuláře pro snadné zadávání dat a sestavy pro efektivní zobrazení požadovaných výstupů. Po vytvoření databáze pak může nastat její hlavní „životní etapa“ – práce s ní (plnění daty, využívání) a její údržba (drobná vylepšení, zálohování) a jistě ještě další činnosti.
Fáze shromažďování požadavků
Dejme tomu, že z rozhovoru se zadavatelem získáme následující požadavky pro databázi Knihovna (nebudu se zabývat rozdělením na funkční a nefunkční požadavky):
-
Databáze uchová ke knize údaj o názvu, oboru, autorovi knihy, roku vydání
-
Databáze uchová o autorovi jen jméno a příjmení
-
Databáze umožní zadat několik oborů, při zadávání knih do databáze bude zadavatel moci z těchto oborů vybírat čili kniha má jeden (nebo více) obor
-
S databází bude pracovat zadavatel (zapisuje nové knihy, zapisuje výpůjčky, návrat knihy, z databáze odstraňuje odepsané knihy, tiskne seznamy knih, tiskne upomínky, seznamy čtenářů s upomínkou, seznamy knih, které má půjčené čtenář, může nastavit interval výpůjčky – např. jeden měsíc)
-
Záznam o výpůjčce bude obsahovat jméno, příjmení, u studenta třídu, datum výpůjčky, datum předpokládaného vrácení (vygeneruje se samo dle nastavení)
-
Databáze umožní při zadávání knih zadavateli vybírat z autorů, popř. dopsat nového autora
-
Databáze umožní, že kniha může mít více autorů (a samozřejmě autor může mít více knih)
-
Databáze umožní, že kniha může mít více oborů (a samozřejmě daný obor může být přiřazen více knihám)
-
Databáze umožní zobrazení nebo výpis knih podle oborů, podle data vydání, podle autorů, podle abecedy – názvů
-
Databáze umožní zobrazit nebo i vypsat záznam výpůjček knih vybraného půjčovatele (třídy, ze které vypůjčovatel je, knihy, data výpůjčky a data, kdy skončila regulérní výpůjční lhůta)
-
Databáze umožní zobrazit všechny vypůjčovatele z jedné třídy
-
Databáze umožní, aby se třída vypůjčovatele v novém školním roce zvýšila, umožní zobrazení nebo výpis studentů, kteří budou v daném školním roce končit studium
-
Databáze umožní nastavit výpůjční dobu
-
Databáze umožní výpis těch vypůjčovatelů, kteří výpůjční dobu překročili
-
Databáze zaznamená historii upomínek každého čtenáře
-
Záznam o upomínce bude obsahovat jméno a příjmení čtenáře, název knihy, datum výpůjčky, datum vrácení a dobu překročení termínu výpůjčky
Fáze analýzy požadavků
Nejdřív vyznačíme v textu zvýrazněním vhodných podstatných jmen možné entity (budoucí tabulky) a jejich vlastnosti (atributy, budoucí sloupce tabulek). Slova, která by mohla představovat entity, označím tučným písmem, atributy těchto entit značím tučnou kurzivou.
-
Databáze uchová ke knize údaj o názvu, oboru, autorovi knihy, roku vydání
-
Databáze uchová o autorovi jen jméno a příjmení
-
Databáze umožní zadat několik oborů, při zadávání knih do databáze bude zadavatel moci z těchto oborů vybírat
-
S databází bude pracovat zadavatel (zapisuje nové knihy, zapisuje výpůjčky, návrat knihy, z databáze odstraňuje odepsané knihy, tiskne seznamy knih, tiskne upomínky, seznamy čtenářů s upomínkou, seznamy knih, které má půjčené čtenář, může nastavit interval výpůjčky – např. jeden měsíc)
-
Záznam o výpůjčce bude obsahovat jméno, příjmení, u studenta třídu, datum výpůjčky, datum předpokládaného vrácení (vygeneruje se samo dle nastavení)
-
Databáze umožní při zadávání knih zadavateli vybírat z autorů, popř. nového autora dopsat
-
Databáze umožní, aby kniha mohla mít více autorů (a samozřejmě aby autor mohl mít více knih)
-
Databáze umožní, aby kniha mohla mít více oborů (a samozřejmě daný obor může být přiřazen více knihám)
-
Databáze umožní zobrazení nebo výpis knih podle oborů, podle data vydání, podle autorů, podle abecedy – názvů
-
Databáze umožní zobrazit nebo i vypsat záznam výpůjček knih vybraného půjčovatele (třídy, ze které vypůjčovatel je, knihy, data výpůjčky a data, kdy skončila regulérní výpůjční lhůta)
-
Databáze umožní zobrazit všechny vypůjčovatele z jedné třídy
-
Databáze umožní, aby se třída vypůjčovatele v novém školním roce zvýšila, umožní zobrazení nebo výpis studentů, kteří budou v daném školním roce končit studium
-
Databáze umožní nastavit výpůjční dobu
-
Databáze umožní výpis těch vypůjčovatelů, kteří výpůjční dobu překročili
-
Databáze zaznamená historii upomínek každého čtenáře
-
Záznam o upomínce bude obsahovat jméno a příjmení čtenáře, název knihy, datum výpůjčky, datum vrácení a dobu překročení termínu výpůjčky
V požadavcích je záměrně ponechána jistá nejasnost v terminologii: přijdete jistě sami na to, že slovo čtenář zde znamená totéž co student, půjčovatel i vypůjčovatel. Všechna tato slova povedou tedy k jediné tabulce, kterou už v databázi máme, jmenuje se Ctenar. Ve složitějším případě by bylo jistější připravit jakýsi slovníček pojmů a synonyma nahradit jen jedním slovem.
Odbočka – prozatímní stavba databáze
Připomeňme si nyní tabulky, které jsme zatím v databázi připravili:
-
Spisovatel(AutorID, Příjmení, KřestníJméno).
-
Kniha(KnihaID, Nazev, AutorID, Obor (text)).
-
Obor(Obor (text)) ... číselník pro obory.
-
Ctenar(CtenarID, Prijmeni, Jmeno, TridaPuvodni, DatumTridyPuvodni, TridaSoucasna).
-
Trida(Trida) ... číselník pro třídy.
Předběhněme na chvíli a podívejte se, jak by se tento návrh dal graficky znázornit v diagramu entit budoucí databáze a vztahů mezi nimi, v tzv. ER diagramu (entitně – relační diagram, též ERD). ER diagramy v tomto dílu byly nakresleny v open-source programu Workbench, určeném přednostně pro databáze MySQL.
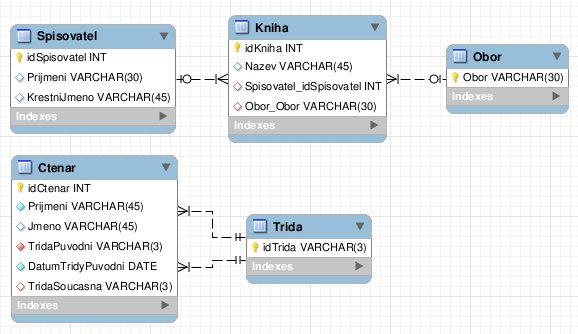 Počáteční verze databáze, znázorněná v ER
diagramu
Počáteční verze databáze, znázorněná v ER
diagramu
Nemáme prostor na podrobný popis diagramu, a tak pokud vám následující body nebudou jasné, navštivte třeba stránku z blogu Lee Richardsona, kde je zde použitý způsob znázornění (Crow's Foot notace, „vraní nožky“ ve schématu označují konec vazby typu M) pěkně vysvětlen. Z diagramu vyčtete mj. toto:
-
Program Workbench doplní do tabulek automaticky cizí klíče po vytvoření vazby a pojmenuje je podle svého schématu. My jsme je v předchozím schématu pojmenovali trochu jinak (např. cizí klíč Spisovatel_idSpisovatel je v našem schématu pojmenován AutorID).
-
Prozatímní návrh předpokládá, že jeden spisovatel může být autorem více knih, ale každá kniha má jen jednoho autora (nebo žádného – to znázorňuje symbol nuly na konci vazby a prázdný červený kosočtverec u cizího klíče Spisovatel_idSpisovatel). Prázdný kosočtverec u cizího klíče říká, že tento cizí klíč nemusí mít nutně zadánu hodnotu (jak to známe z předchozího dílu; říká se také, že entita nemá povinné členství ve vazbě).
-
Podobně jeden obor se může týkat více knih, ale každá kniha by podle návrhu byla přiřazena jen k jednomu (nebo k žádnému) oboru.
-
Ve znázornění návrhu ER diagramem platí, že jedna třída může obsahovat víc čtenářů, ale každému čtenáři bude při zápisu zadána právě jedna třída (to ukazuje plný červený kosočtverec u cizího klíče TridaPuvodni). U čtenáře musíme také zadat hodnotu příjmení a datum zápisu původní třídy. Nenechte se zmást tím, že vazby „nekončí u správných atributů“ TridaPuvodni a TridaSoucasna, jde jen o vyznačení vazby mezi entitami.
-
Je také vidět, že v návrhu něco není v pořádku: chybí vazba mezi tabulkou Kniha a Ctenar (to jste zjistili už na konci předchozího dílu). Přitom není snadné říci, jakého typu tato vazba bude. Mohlo by jít o vazbu 1 – M, protože jeden čtenář může mít půjčeno více knih. Zároveň ale jedna kniha může být půjčena (během času) více čtenářům. Pokud bychom chtěli zaznamenávat historii výpůjček, měla by tedy tato vazba být spíš typu M – M. Vrátíme se k ní později.
Návrat k analýze požadavků – entity
Z rozboru slov, zvýrazněných v požadavcích, zjistíte důležité podněty k vylepšení právě uvedeného prozatímního návrhu:
-
Tabulka Kniha by podle požadavků měla obsahovat ještě jeden sloupec, udávající rok vydání knihy, nazvěme ho RokVydani.
-
Databáze by kromě uvedených pěti tabulek mohla obsahovat ještě tabulku výpůjček, nazvěme ji Vypujcka (viz např. body požadavků číslo 4, 5, 10). Tato tabulka by měla mít vazbu na tabulku Ctenar a na tabulku Kniha. Navíc bude obsahovat datum výpůjčky a snad i datum (termín) nejzazšího předpokládaného vrácení dle doby výpůjčky (i když tento údaj by mohl být jen v případě potřeby v databázi dopočítán funkcemi pro datum).
-
Měli bychom přidat také tabulku pro záznam upomínek čtenáře (podle bodů požadavků číslo 4, 15, 16), dejme jí název Upominka. V bodě šestnáct se říká: Záznam o upomínce bude obsahovat jméno a příjmení čtenáře, název knihy, datum výpůjčky, datum vrácení a dobu překročení termínu výpůjčky. Víte už, že díky vazbám ve skutečnosti postačí odkaz na čtenáře, na knihu a na výpůjčku (na tabulku Vypujcka). Dobu překročení dopočte Base.
-
Databáze by měla umožnit nastavení výpůjční doby (bod č. 13, pro jednoduchost uvažujme, že bude pro všechny čtenáře a knihy stejná). Měli bychom tedy vytvořit další tabulku, která by tento údaj obsahovala. Nazvěme ji třeba Nastaveni, protože bude obsahovat nastavení databáze. Kromě výpůjční doby bychom do ní mohli uložit název zařízení, ve kterém knihovna je (domácí knihovna, školní knihovna kabinetu fyziky apod.), dál třeba adresu zařízení. Tyto údaje se mohou hodit pro různé výpisy neboli sestavy. Tabulku Nastaveni bychom do výsledku analýzy požadavků – ER diagramu – ani kreslit nemuseli, u podobných údajů to není zvykem. V diagramu ji uvedu pro úplnost.
A nyní ještě vztahy mezi budoucími tabulkami:
Tentokrát se zaměříme na entity (tučné písmo) a vazby mezi nimi (tučná kurzíva). Značení vazeb by bylo lepší více odlišit, abychom si je nespletli s vlastnostmi (atributy) entit v předchozím rozboru požadavků; redakční systém webu OpenOffice.cz ale jiné formátování nyní neumožňuje. Kvůli úspoře místa vyberu jen několik požadavků, které by nás mohly kvůli vazbám zajímat:
...
3. Databáze umožní zadat několik oborů, při zadávání knih do databáze bude zadavatel moci vybírat z těchto oborů čili kniha má jeden (nebo více) obor
...
7. Databáze umožní, že kniha může mít více autorů (a samozřejmě autor může mít více knih)
8. Databáze umožní, že kniha může mít více oborů (a samozřejmě daný obor může být přiřazen více knihám)
…
ER diagram
Výsledkem analýzy požadavků (entit, atributů a vazeb) bude nový ER (entitně – relační) diagram. Mohl by vypadat následovně:
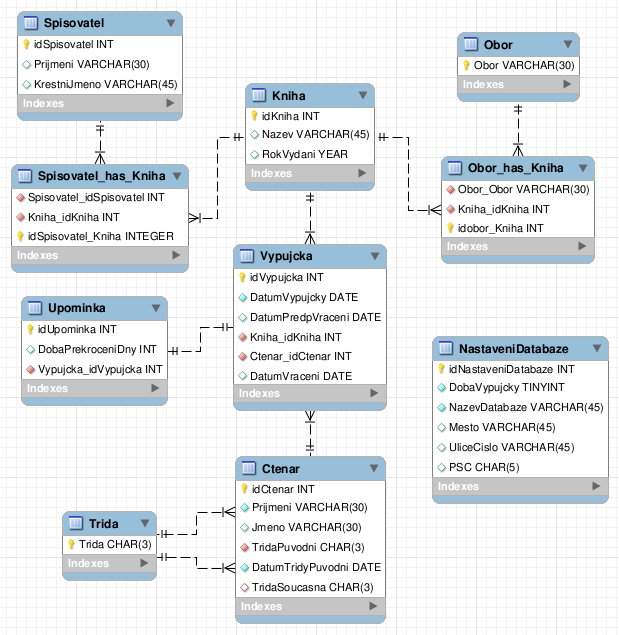 ER diagram vylepšeného konceptuálního
modelu podle požadavků
ER diagram vylepšeného konceptuálního
modelu podle požadavků
V diagramu se už setkáváme s řešením problému vazby M – M mezi dvěma tabulkami. Tato vazba se uskuteční rozdělením na dvě vazby 1 – M s pomocí třetí tabulky, vložené mezi dvě původní. Takovou pomocnou tabulkou je Spisovatel_has_Kniha mezi tabulkami Kniha a Spisovatel a tabulka Obor_has_Kniha mezi tabulkami Kniha a Obor. Poslední tabulky tohoto typu v diagramu se týká otázka na konci dílu.
Všimněte si, že v ER diagramu se nezobrazují činnosti, které s daty budeme v databázi provádět (zobrazení výpůjček, zadávání knih, autorů a oborů, zápis čtenáře, výpis upomínek apod., viz další odstavec). Tento diagram má za úkol zobrazit jen zástupce trvale uložených dat – entity – a vazby mezi nimi. Ukázka části jiného ERD pro knihovnu je na stránce o entitách z níže uvedeného zdroje Vysoké školy ekonomické v Praze.
Diagram případů užití (Use case diagram)
Analýze požadavků může pomoci také grafické znázornění činností, které budou uživatelé (tzv. aktéři, actors) provádět. Více pohledů na požadavky umožňuje totiž jejich vzájemné opakované vylepšování a doplňování. Zde uvádím tzv. diagram případů užití (Use Case Diagram), všimněte si, že jako aktér může být označen i čas, pokud nějaká činnost v systému má nastat v jistém čase. Diagram jistě není úplný, ale mohl by nás přivést k vylepšení seznamu požadavků a naopak v průběhu shromažďování požadavků bychom mohli doplňovat tento diagram.
 Možný diagram případů užití
Možný diagram případů užití
Závěr
Obsah tohoto dílu byl možná obtížnější a jeho čtení nebylo pro čtenáře kurzu práce s Base nutné. Získali jsme ale konceptuální model (ER diagram), od kterého se bude odvíjet naše další práce na databázi Knihovna v Base. Tu začneme převodem do tabulek a vazeb v dalším díle.
Vytvořený ER diagram je sice z pohledu skutečných databází značně jednoduchý, ovšem na začátečníka může působit jinak. Proto pro příští díl připravím ještě jedno schéma, které bude jednodušší a může posloužit jako vzor pro tvorbu snazší varianty databáze. Tím se v dalších dílech práce na databázi Knihovna rozdělí na jednodušší a složitější verzi, aby si mohl práci s Base procvičit na jedné straně třeba student počátečních ročníků střední školy, na straně druhé třeba maturant v semináři z informatiky.
Zdroje dalších informací, prameny tohoto dílu
-
Velmi podrobný výukový web RNDr. Heleny Palovské, Ph.D. pro cvičení předmětu Databáze oboru Informatika na Vysoké škole ekonomické v Praze
-
Seriál o vývoji databází, zaměřený na MySQL
-
Skriptum Doc. Miloše Šedy z Vysokého učení technického v Brně
-
Skriptum Jiřího Hronka z Přírodovědecké fakulty Univerzity Palackého v Olomouci
-
Dvoje skripta na stránce Ing. Zdeňky Telnarové, Ph. D. z Ostravské univerzity
-
Z literatury uvádím např. knihu D. Lacka: SQL Hotová řešení, velmi kvalitní jsou materiály J. Zendulky a I. Rudolfové z Fakulty informačních technologií Vysokého učení technického v Brně.
Otázky na závěr – Shrnutí pátého dílu (návrh databáze)
-
Připomeňte fáze vývoje databáze. Které z nich jsou naznačeny v tomto díle?
-
Najděte ještě jednu tabulku, která ve výsledném ER diagramu uskutečňuje vazbu M – M pomocí dvou vazeb 1 – M.
-
Najděte v diagramu také jedinou vazbu 1 – 1.
-
Zkuste navrhnout (nakreslit na papír, vytvořit v programu Workbench apod.) ER diagram jednodušší verze databáze Knihovna.
Co vás čeká v dalším díle?
Na tvorbu konceptuálního modelu navážeme logickým návrhem databáze: tvorbou tabulek a vazeb. Zároveň si vyzkoušíme převod vazby M – M na dvě vazby 1 – M. V praktické části pak budete moci vytvořit další tabulky a vazby mezi nimi. Jestli v dílu zbude místo, budou také podrobněji rozebrány možnosti vazeb mezi tabulkami v relační databázi a v Base.








