
 Další díl volné série u funkcích v Calcu pokračuje textovými funkcemi pro záměnu a nahrazování, převody na čísla a z čísel podobnými možnostmi.
Další díl volné série u funkcích v Calcu pokračuje textovými funkcemi pro záměnu a nahrazování, převody na čísla a z čísel podobnými možnostmi.
Předchozí díly volného seriálu:
- Funkce pro práci s textem – spojování, pročištění, vyhledávání
- Možnosti kopírování a vkládání obsahu buněk
- Vkládání a úpravy funkcí pomocí průvodce
- Funkce v OpenOffice.org Calc – síla, kterou je obtížné zkrotit
- Logické funkce 2 – AND, OR
- Logické funkce 1 - funkce IF
Jestliže potřebujete v buňce nahradit část textu jiným, máte k dispozici dvě funkce - REPLACE a SUBSTITUTE. REPLACE využijete, pokud znáte pozici a počet znaků, které chcete nahradit novým textem, nebo chcete na určitou pozici vložit nový text; např. výsledkem REPLACE("vlož slovo";5;1;" nové ") bude „vlož nové slovo". Nelze nahradit nulový počet znaků, proto je nutné nahradit mezeru a doplnit ji do vkládaného textu.
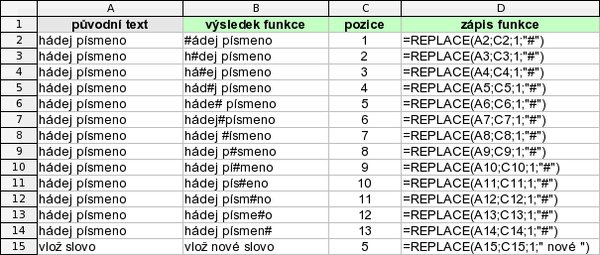 Nahrazení textu na známé pozici
Nahrazení textu na známé pozici
V případě, že nejdříve potřebujete v buňce najít text, který poté chcete nahradit novým, použijte funkci SUBSTITUTE, která zadaný text najde a zároveň ho nahradí novým. Nahradit lze buďto všechny výskyty hledaného textu, nebo jen jeden určitý, vizte následující příklad.
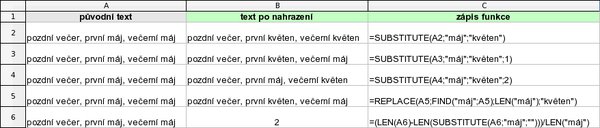 Vyhledání a nahrazení zadaného řetězce novým
Vyhledání a nahrazení zadaného řetězce novým
Řádek 6 v našem příkladu je ukázkou, jak lze s trochou logiky a skládáním funkcí získat „nové" funkce, které v Calcu nejsou (a ani v MS Excelu):
=(LEN(A6)-LEN(SUBSTITUTE(A6;"máj";"")))/LEN("máj")
Zde je to vzorec, který v dané buňce určí počet výskytů zadaného řetězce. Finta je v tom, že se nejprve z původního textu odstraní všechny výskyty zadaného řetězce, délka výsledku se porovná s délkou původního textu a výsledný rozdíl se vydělí délkou hledaného (odstraněného) řetězce, čímž dostanete počet jeho odstranění=výskytů.
Při SUBSTITUTE("xx";"x";"xx") bude výsledkem „xxxx", tzn. že SUBSTITUTE nejprve vyhledá všechny výskyty a teprve potom je najednou všechny nahradí. Pokud by totiž toto prováděl iteračně, tj. našel první výskyt, nahradil ho, pak našel další výskyt, nahradil ho, atd., atd., tak v uvedeném případě by práci nikdy nedokončil a nahrazoval by teoreticky do nekonečna.
Jestliže potřebujete porovnat shodu dvou řetězců, máte na výběr z funkcí = (ano, pouze rovnítko) a EXACT. Obě rozlišují velikost písmen a obě dokáží porovnávat text i čísla i výsledky vzorců. Pokud buňka A1 obsahuje text „Aa" a buňka A2 text „aA", tak výsledek =EXACT(A1;A2) i =A1=A2 bude v obou případech NEPRAVDA/FALSE, protože se řetězce liší ve velikosti písmen. Pokud potřebujete porovnat shodu řetězců bez ohledu na velikost písmen, musíte si pomoci jejich konverzí na velká nebo malá písmena, tj. =EXACT(LOWER(A1);LOWER(A2)), resp. =EXACT(UPPER(A1);UPPER(A2)). Pak již dostanete jako výsledek PRAVDA/TRUE.
Pro generování opakujícího se textu lze využít funkci REPT, která jako vstup bere řetězec k opakování a počet těchto opakování ve výsledku, např. REPT("X";99) zobrazí v buňce text o 99 znacích X.
Speciálními funkcemi pro práci se znaky jsou CHAR a CODE, které se můžou hodit spíše programátorům - první jmenovaná převede zadané číslo na znak podle aktuální tabulky znaků, např. CHAR(65) vrátí znak „A"; přípustné jsou hodnoty 1-255. CODE se chová opačně, tj. ze zadaného znaku (resp. prvního znaku zadaného řetězce) vrátí jeho kód, např. CODE("BCD") vrátí hodnotu 66.
Pokud chcete v některé buňce zobrazit vzorec z jiné buňky, jako vidíte v příkladech, použijte funkci FORMULA s odkazem na buňku se vzorcem. Pro zobrazení vzorců ve všech buňkách, namísto jejich výsledků, použijte z menu Nástroje | Volby | OpenOffice.org Calc | Zobrazit | Zobrazení | Vzorce.
K převodům mezi textem a čísly existuje celá řada funkcí. Mnohé z nich je přímo potřeba použít např. při získávání čísel z textů. Jestliže máte např. sadu nějakých kódů, ze kterých potřebujete získat čísla a s nimi dále pracovat, budete potřebovat funkci VALUE, která převádí text na číslo, jak je vidět na dalším příkladu.
 Převod textu na číslo
Převod textu na číslo
Ačkoliv se hodnota ve sloupci B může jevit jako číslo, je to text, protože je výsledkem funkce MID. Proto je také výsledek ve sloupci C špatný, protože se sčítá text a číslo. Až vzorec ve sloupci D je správný, protože před sečtením je výsledek funkce MID převeden na číslo pomocí funkce VALUE. Toto opomenutí bývá častým zdrojem chyb a špatných výsledků.
O něco složitější funkcí k převodu textu na číslo v desítkové soustavě je DECIMAL, která zvládá i různé číselné soustavy na vstupu. Kromě běžné desítkové se nejčastěji používá šestnáctková (hexadecimální) a dvojková (binární). V DECIMAL můžete zadat soustavy 2-36. Výsledkem DECIMAL("a1b1c1";16) bude 10 596 801, DECIMAL("10101";2) dá 21. Funkce VALUE("123") se pak dá zapsat jako DECIMAL("123";10), výsledek je stejný.
Pokud potřebujete převádět čísla mezi jednotlivými soustavami, podívejte se na funkce HEX2BIN, HEX2DEC, DEC2BIN, DEC2HEX a podobné.
Opačnou funkcí k DECIMAL je BASE, pomocí které získáte z celého kladného desítkového čísla jeho textový ekvivalent v zadané číselné soustavě o zadaném počtu znaků. Lze takto formátovat i desítková čísla, např. BASE(666;10;5) vrátí text „00666", BASE(666;16;5) pak „0029A". Opět mějte na paměti, že výsledkem je text a pro další počítání s ním je potřeba zase použít VALUE.
Pokud potřebujete formátovat desetinné číslo či oddělovat řády tisíců, použijte funkci FIXED. Výsledkem je opět text, např. FIXED("1024,56";4;0) vrátí „1 024,5600". Třetí parametr ve funkci určuje, zda se budou oddělovat tisíce (0 - výchozí hodnota) nebo ne (1). Použije se oddělovač tisíců nastavený ve vašem pracovním prostředí.
Ještě větší volnost při formátování čísel na text vám poskytne funkce TEXT, které lze přímo zadat formát výstupu. Výsledkem TEXT(1024,56;"000 ###,000") bude „001 024,560". Znak 0 se ve formátu používá pro povinný počet míst, # pro volitelný počet míst, % pro převod na procenta. TEXT kromě samotného formátování provádí i zaokrouhlování či násobení 100 při převodu na procenta, jak je vidět v následujících příkladech.
 Formátování čísel na text
Formátování čísel na text
Calc disponuje ještě funkcemi pro převod z a na římské číslice, např. ROMAN(1989) vrátí text „MCMLXXXIX", ARABIC("MCM") pak 1900. Funkce zvládají hodnoty v rozsahu 0 až 3999.
Uvedené příklady si můžete stáhnout: Textové funkce 2 - příklady, stejně jako přehlednou tabulku funkcí: Textové funkce 2 - přehledová tabulka.









