
 Text v buňkách můžete pomocí funkcí vyhledávat, upravovat, nahrazovat, transformovat a provádět s ním mnohá další kouzla. V minulých dílech jste se již naučili vzorce vkládat, kopírovat, upravovat, takže nadále se již budeme zabývat samotnými funkcemi a jejich využitím.
Text v buňkách můžete pomocí funkcí vyhledávat, upravovat, nahrazovat, transformovat a provádět s ním mnohá další kouzla. V minulých dílech jste se již naučili vzorce vkládat, kopírovat, upravovat, takže nadále se již budeme zabývat samotnými funkcemi a jejich využitím.
Přdchozí díly volného seriálu:
- Funkce v OpenOffice.org Calc – síla, kterou je obtížné zkrotit
- Vkládání a úpravy funkcí pomocí průvodce
- Možnosti kopírování a vkládání obsahu buněk
- Logické funkce 1 - funkce IF
- Logické funkce 2 – AND, OR
Velmi často je potřeba spojit obsah různých buněk do jedné výsledné. V případě sčítání čísel použijeme funkci součet (+), v případě textu je to operátor &, tedy např. =A1&B1. Zde nezapomínejte na to, že mezi slova a věty patří mezery, takže je potřeba vzorec patřičným způsobem upravit, tj. např. =A1&" "&B1. Spojovat takto můžete text i čísla, např.
="výška "&A2&" cm x šířka "&B2&" cm = "&C2&" cm2"
kdy v buňkách A2, B2 a C2 jsou příslušné číselné údaje. Následující obrázek obsahuje praktickou ukázku.
 Spojování obsahu buněk
Spojování obsahu buněk
Pokud vás dlouhá změť znaků & mate, použijte namísto toho funkci CONCATENATE, jejímž výsledkem je spojení zadaných parametrů. Výše uvedený příklad tedy zapíšete jako
=CONCATENATE("výška ";A2;" cm x šířka ";B2;" cm = ";C2;" cm2")
Pokud chcete zachovat bezproblémovou kompatibilitu s formátem XLS, nepoužívejte v této funkci více než 30 parametrů.
Další užitečnou funkcí je TRIM, která odstraní ze zadaného textu nadbytečné mezery na začátku a na konci. Uprostřed textu pak převede vícenásobné mezery na jednoduché. Jak jsme si řekli již dříve, funkce je možné na sebe navazovat - zde se pak nabízí spojení
=TRIM(CONCATENATE(text1;text2;text3))
 Vyčištění nadbytečných mezer po spojení textů
Vyčištění nadbytečných mezer po spojení textů
TRIM se vám bude hodit také v případě porovnávání a vyhledávání řetězců, kdy jedna zapomenutá mezera na konci navíc může znamenat neshodu. Čisticí úlohu má také funkce CLEAN, která ze zadaného textu odstraňuje netisknutelné znaky. K převodu daného textu na malá písmena použijte funkci LOWER, na velká pak funkci UPPER. Použijete-li funkci PROPER, budou začátky všech slov velkými písmeny, jak je vidět na následujícím příkladu.
 Změna velikosti písmen
Změna velikosti písmen
Často je potřeba ze zadaného textu získat jeho část. K tomu vám poslouží několik funkcí. LEFT vrací z textu zadaný počet znaků zleva, RIGHT zprava a MID pak od zadané pozice v řetězci, např. výsledkem MID("Ahoj";2;2) bude "ho". Další příklady vidíte na obrázku.
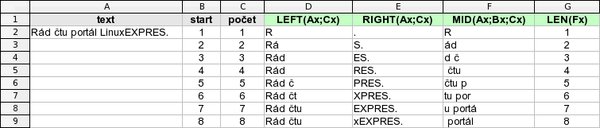 Získání zvolené části textu
Získání zvolené části textu
Málokdy je však předem známo, kolik znaků nebo z které pozice je potřeba text získat, resp. se tyto údaje liší v závislosti na skutečném obsahu buněk - např. chcete pouze první slovo z druhé věty. Tento již složitější úkol pomohou vyřešit výše uvedené funkce v kombinaci s funkcemi pro vyhledávání FIND a SEARCH.
Funkce FIND hledá zadaný text ve zvoleném řetězci od stanovené pozice. Pokud ho nalezne, vrátí pozici začátku jeho prvního výskytu, jinak chybovou hodnotu #VALUE!. Vše nejlépe vysvětlí krátký příklad: FIND("text";"Prohledávaný text"). Výsledkem bude číslo 14, protože „text" začíná v „Prohledávaný text" na 14. znakové pozici. Funkce FIND rozlišuje velikost znaků („case-sensitive"), takže FIND("Text";"Prohledávaný text") skončí chybovým hlášením #VALUE!.
„Case-sensitive" znamená, že jsou rozlišována malá a velká písmena; např. „Ahoj" pak není to samé jako „ahoj" či „AHOJ" apod.
FIND může mít ještě třetí parametr, kterým je pozice, od které se má začít hledat: FIND("tam";"tam a tam";2). Výsledkem bude hodnota 7.
Funkce SEARCH je velmi podobná - liší se v tom, že u ní nezáleží na velikosti písmen a lze v ní použít zástupné znaky - regulární výrazy, které výrazným způsobem rozšiřují možnosti hledání. Jejich použití však vyžaduje určité znalosti a zkušenosti, které přesahují rámec tohoto článku. Pro použití regulárních výrazů v některých funkcích musí být aktivováno jejich vyhodnocování přes menu Nástroje | Volby... | OpenOffice.org Calc | Spočítat zaškrtnutím Povolit regulární výrazy ve vzorcích.
Nechť je v buňce A2 text „První věta. Druhá věta." Jak získat první slovo z druhé věty? Nejprve z textu vypreparujte druhou větu - předpokladem je, že druhá věta začíná po první tečce v textu, takže vzorec =MID(A2;FIND(".";A2)+1;LEN(A2)) vrátí řetězec „ Druhá věta." K výsledku funkce FIND(".";A2) je zde nutné přičíst jedničku, protože výsledkem je pozice první tečky a vy chcete vrátit znaky až za první tečkou. První slovo pak dostanete tak, že si necháte vypsat všechny znaky až po první mezeru (neuvažuje se zde, že by za prvním slovem mohla být např. čárka). Protože po tečce za větou bývá obvykle mezera (nemusí to ale tak být), odstraňte dále ze získané druhé věty nadbytečné mezery pomocí funkce TRIM:
=TRIM(MID(A2;FIND(".";A2)+1;LEN(A2)))
Nyní získáte první slovo tak, že v druhé větě najdete pozici první mezery a necháte si vrátit všechny znaky do této pozice:
=LEFT(TRIM(MID(A2;FIND(".";A2)+1;LEN(A2)));FIND(" ";TRIM(MID(A2;FIND(".";A2)+1;LEN(A2))))-1)
Vzorec vypadá složitě, protože obsahuje všechny kroky najednou. Pokud si ale do buňkyA3 vložíte předchozí vzorec TRIM(MID(A2;FIND(".";A2)+1;LEN(A2))), tedy získání druhé věty, zjednoduší se zápis na =LEFT(A3;FIND(" ";A3)-1), tedy že chcete z druhé věty (je nyní v buňce A3) získat zleva o jeden znak méně, než je pozice první mezery ve druhé větě. Výsledkem bude řetězec „Druhá". Použitá funkce LEN vrací délku zadaného textu včetně všech mezer na začátku a na konci.
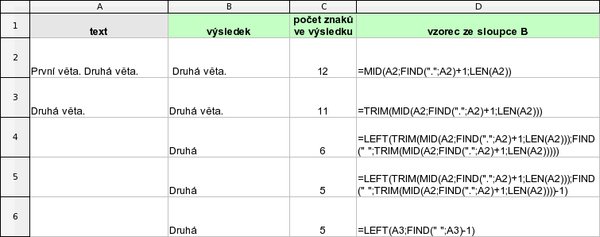 Získání prvního slova z druhé věty
Získání prvního slova z druhé věty
Uvedené příklady si můžete stáhnout: Textové funkce 1 - příklady, taktéž si můžete stáhnout přehledovou tabulku v PDF formátu: Textové funkce - přehledová tabulka.










